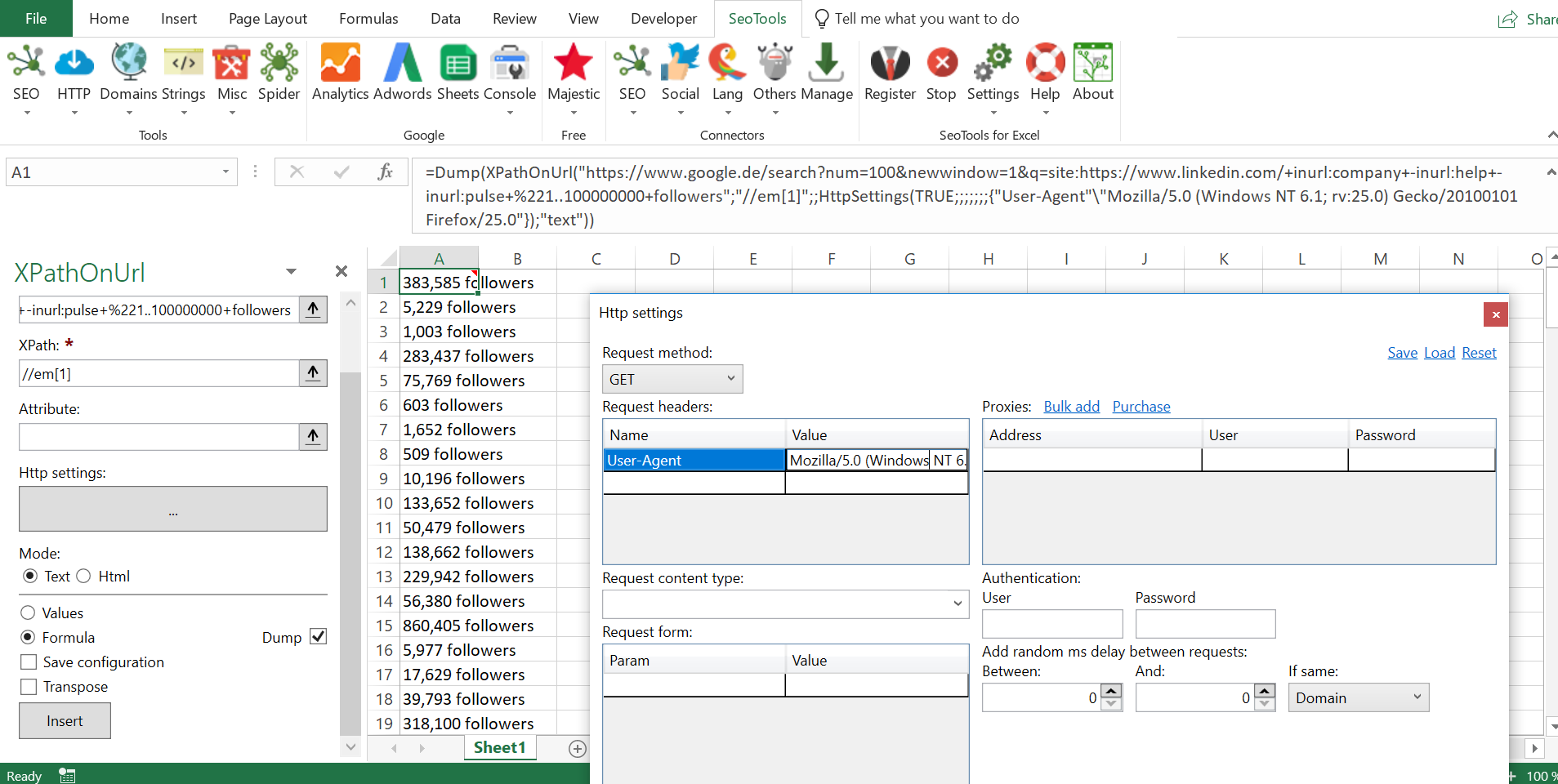
Hi, I'm still not good dealing with xpathonURL yet, can you help me out on how to get the # of followers on this page: https://pe.linkedin.com/company/cencosud-s-a-
I want to make a list of the top companies and see how many followers they have.
So far the place where this information is located is here:
can you guys help create the xpath?.
I tried the following:
=Dump(XPathOnUrl("https://pe.linkedin.com/company/cencosud-s-a-","//p[@class='followers-count']",,,"text"))
Thanks.