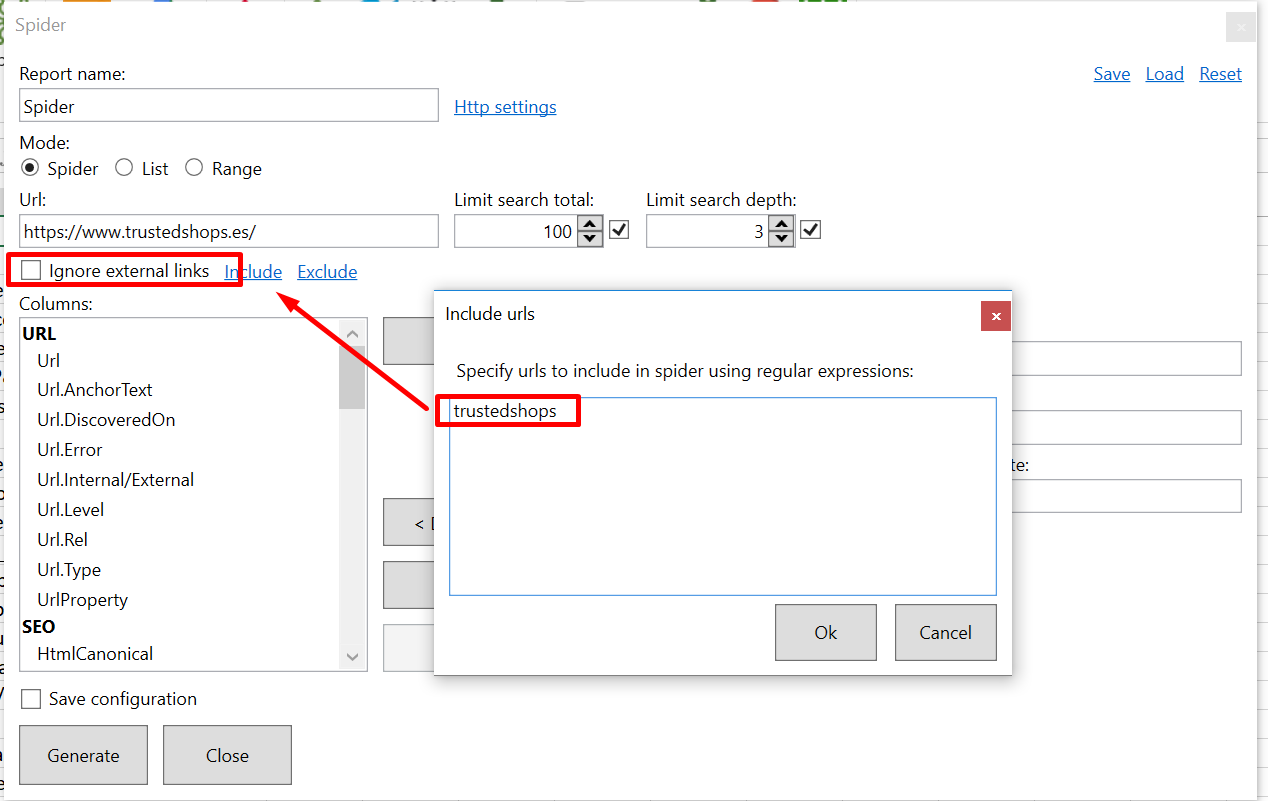
I want to scrape date from a site with the spider.
The site is:
https://www.trustedshops.es/encontrar/?cat=cualquier_categor_a&q=
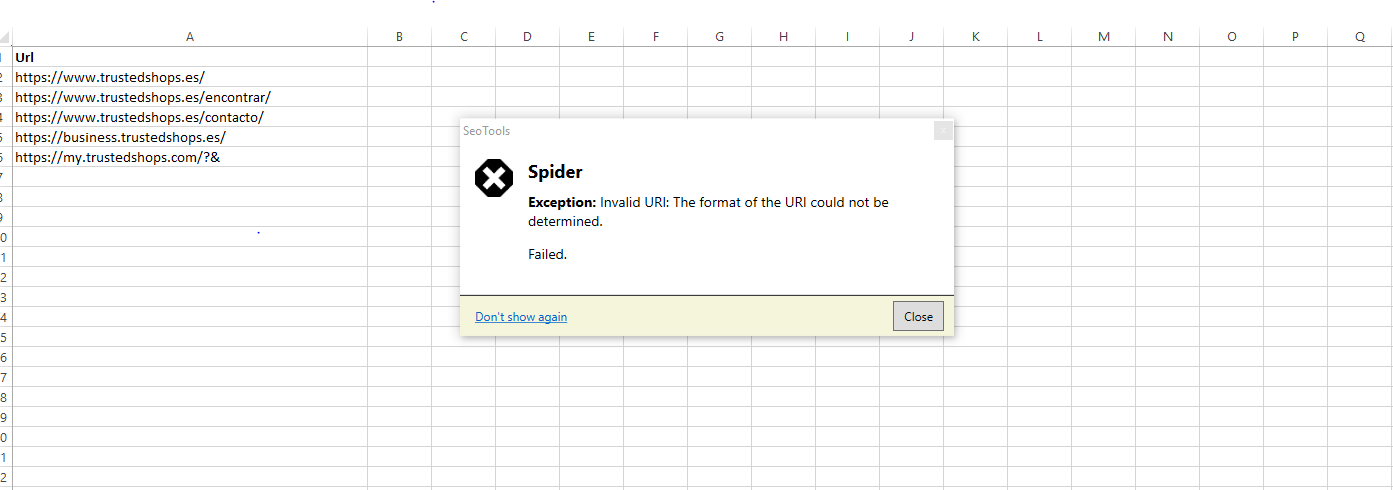
The problem is that I only get a few URLs.
Another problem is, that the data often is on external links.
Example:
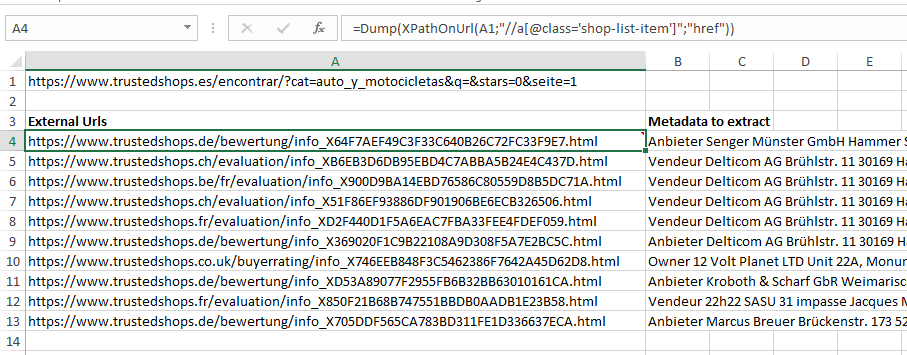
Category "Auto Motocicletas"
https://www.trustedshops.es/encontrar/?cat=auto_y_motocicletas
First result links to:
https://www.trustedshops.ch/evaluation/info_XB6EB3D6DB95EBD4C7ABBA5B24E4C437D.html
Is there a way to scrape the infos ?