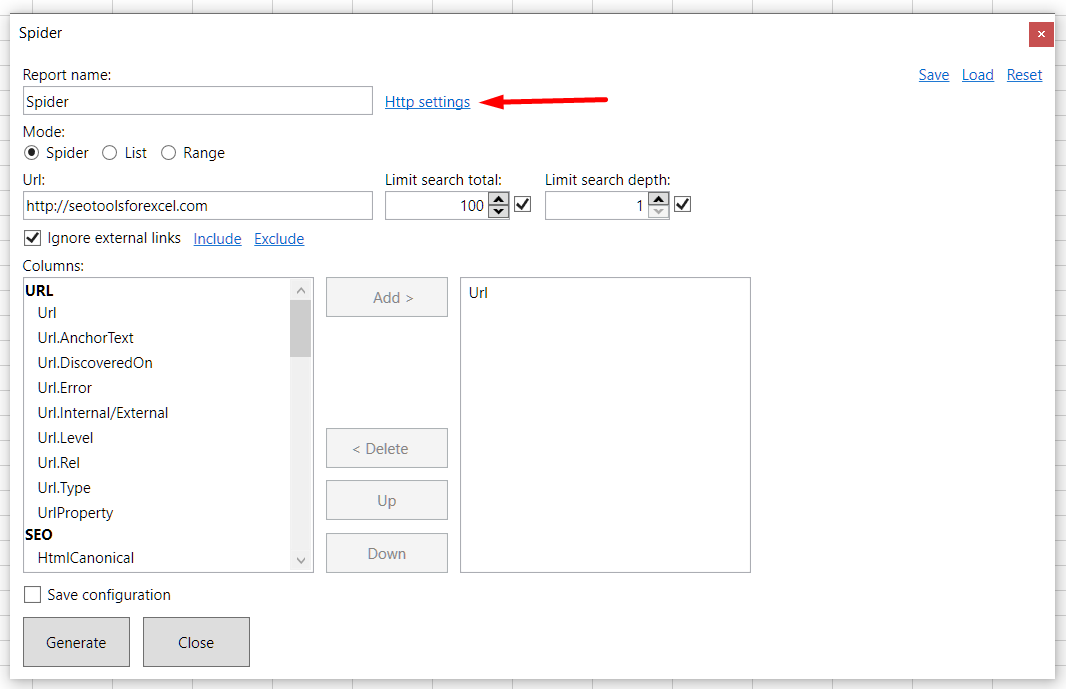
Hi, I used to use Spider on a website to get tons of pages...
I tries again a few minutes ago on the same site but this time nothing works.
I just get one line with no info
I guess the technology hase evolved and the websites protects themselves much better than before ?
Thanks
|Url.AnchorText
|Url.DiscoveredOn => #NUL!
|Url.Error Empty
|Url.Internal/External| => Internal