Hi all,
since a long time I scrape data from startup websites. Since a few month I'm proud to be a pro user 
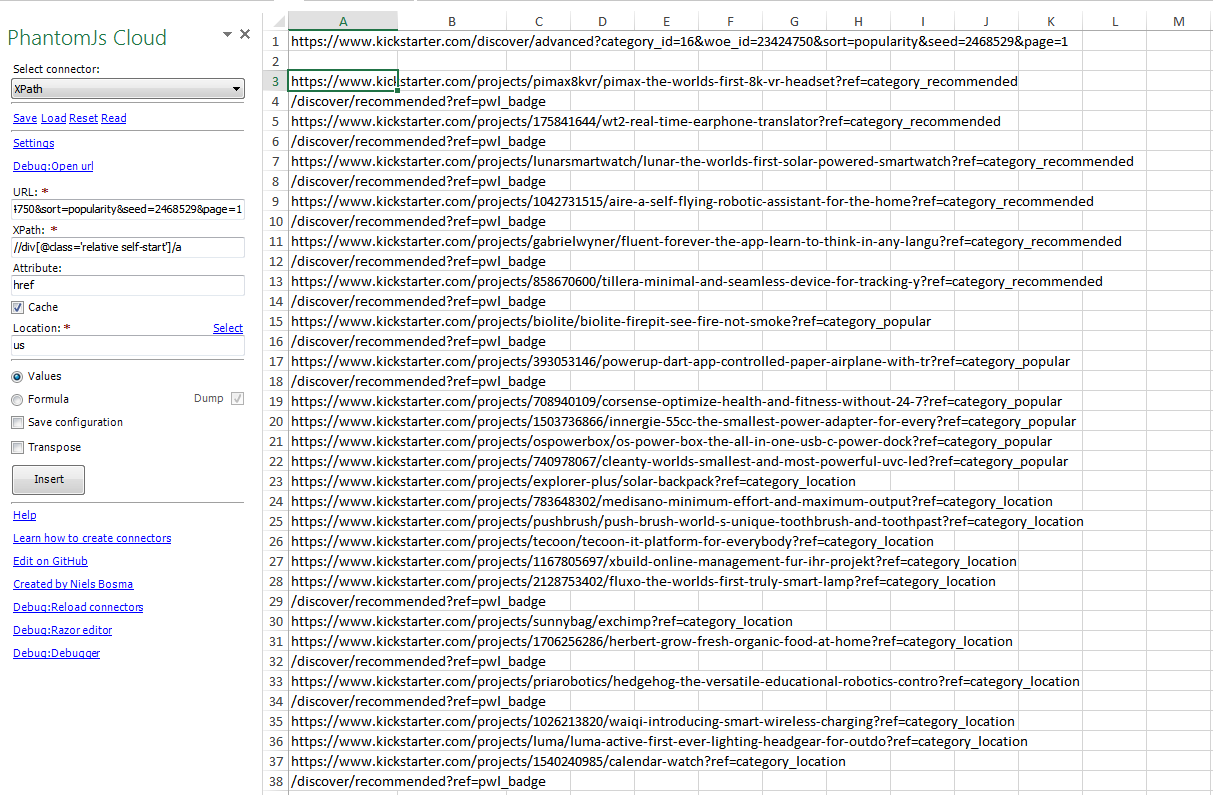
One of the websites changed their sourcecode. Normally I change the XPath and everything works again. But their is one website I can't crawl. --> Link
I need the href values for every startup subsite. In this case the first href should be: https://www.kickstarter.com/projects/explorer-plus/solar-backpack?ref=category_location
and the next one: https://www.kickstarter.com/projects/783648302/medisano-minimum-effort-and-maximum-output?ref=category_location
I can scrape all the attributes around this one, but I don't get this specific href. I used different paths and don#t found a way that works...
Can someone give me an advice????