Hi everyone,
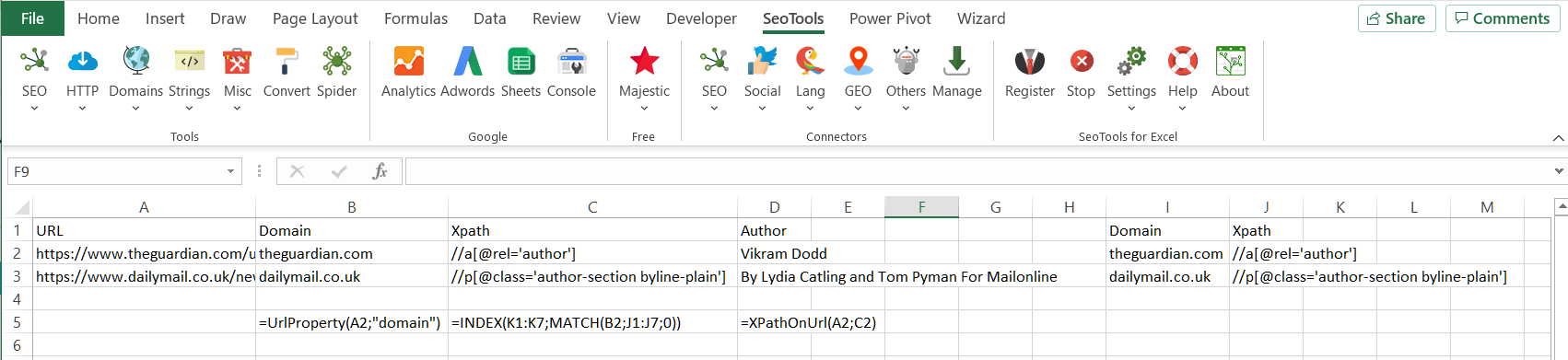
Does anyone know of a way to scrape authors/journalists from articles from various news sites using a common theme?
I've tried using XPath with "//div[@class='author']" but it doesn't seem to work.
Here's are a few URLs so you can see what I need:
- https://www.theguardian.com/uk-news/2021/mar/28/racial-justice-is-key-to-effective-policing-says-npcc-chief-martin-hewitt
- https://www.dailymail.co.uk/news/article-9411757/More-30million-Britons-received-Covid-jab-infections-fall-nearly-week.html
- https://techcrunch.com/2021/03/27/y-combinator-demo-day-dispo-due-diligence/