
Hi !
I want to scrape URLs with a specific anchortext from pages...
What I mean by that: In Cell A1 I have "Anchortext" and in B1 I want to have the URL with that anchortext from the page.
Is this possible?
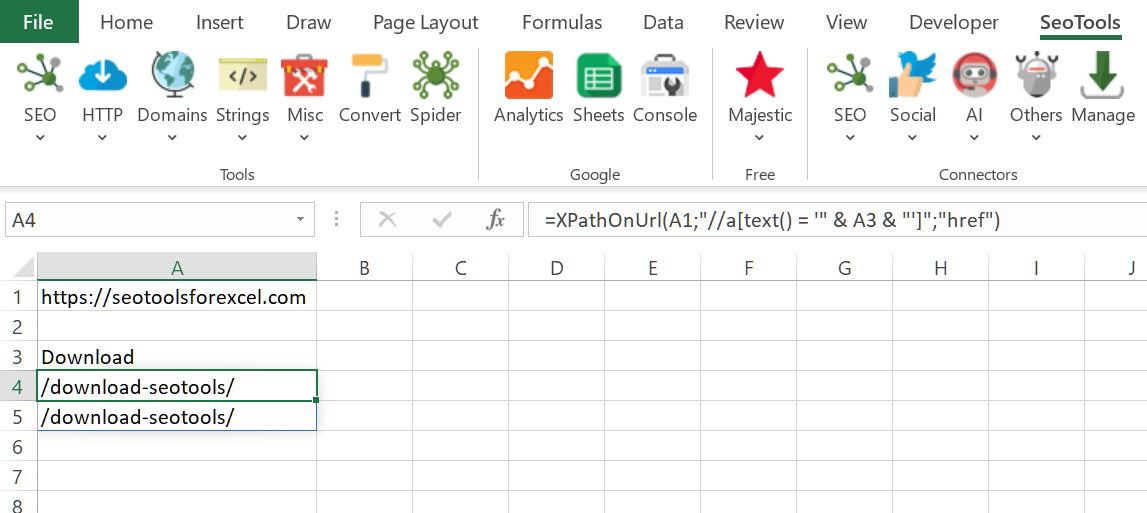
Hmm, does not work for me. Can you copy & paste the formula here ?
What I want to do is to scrape the author profiles out of a list of article URLs:
Example:
https://www.finnewsnetwork.com.au/archives/finance_news_network425663.html
https://www.finnewsnetwork.com.au/journalists/Abbey%20Phillipps
Link to example sheet with the first formula:
https://easyupload.io/5wy7n7
The author profiles can be extracted with the following xpath:
=XPathOnUrl(A1;"//a[contains(@href,'/journalists')]/b")
Thanks ! Works perfect !
By the way, an off topic question: Is it possible to scrape the author URL without having the anchor text?
Sure:
="https://www.finnewsnetwork.com.au" & @XPathOnUrl(A1;"//a[contains(@href,'/journalists')]";"href")
Looks great. But does it work with the root domain or with the article URL as well?
Example:
I want only the author URL from this article (Andy Gregory) https://www.independent.co.uk/climate-change/news/indonesia-forest-fires-palm-oil-nestle-unilever-p-g-desforestation-slash-burn-a9195716.html
Each domain probably requires a different XPath because of different HTML. I recommend right clicking and inspecting, then construct the XPath after the DOM:
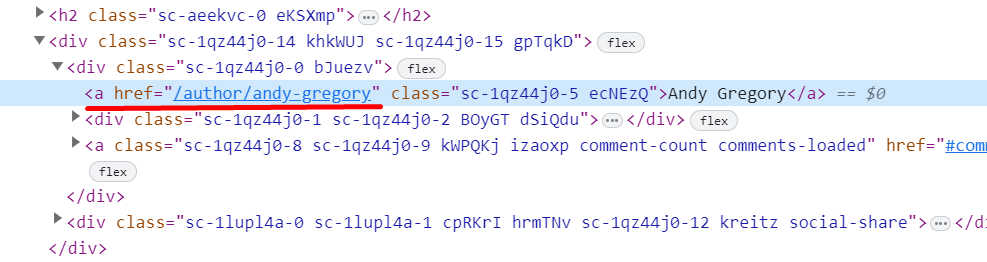


The "@" character is still in your formula

By the way. What should be in A1 ? The root domain or the article URL?
Article URL, attached workbook:
https://easyupload.io/q26t1l
oh, this is awesome, thanks.
But one quick question:
For https://www.diariodemallorca.es/economia/2021/08/09/cnmc-advierte-vuelta-publicidad-television-56088551.html
I get this:
https://www.diariodemallorca.eshttps://www.diariodemallorca.es/autores/matias-valles.html
Two URLs and a different author (not Sara Ledo)
The formula is:
=C32 &@XPathOnUrl(B32;"//a[contains(@href,'/autor')]";"href")
You'll get the first matching link that matches the xpath criteria. Sara Ledo doesn't have a link and that's why you get a different author.