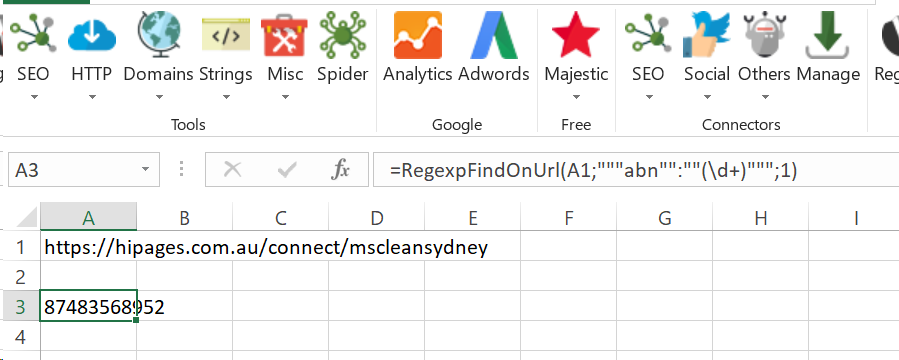
I am trying to scrape some specific content that sits within the <script> section of a page (at the bottom of the page before the end of the tag. It is my understanding that this can't be done with regular XPath, so I will be using PhantomJs cloud via SEOTools for Excel plugin.
Please see sample of code below:
window.__INITIAL_STATE__ = {"questions":{"list":{},"status":{}},"sites":{"list":{"SEOTest":{"joined":"2016-04-17T22:00:31.000Z","threshold":[],"abn":"8724483318952", I want to be able to scrape the text after "ABN" field, so the xpath would return "8724483318952". Can anybody help me with this?