Hi all,
I'm having difficulties extracting the text of Instagram posts if they are longer than a certain amount of characters. In most cases, I just use =HtmlMetaDescription(URL) which works fine, except with the aforementioned cases.
For example, using HtmlMetaDescription on the following post:
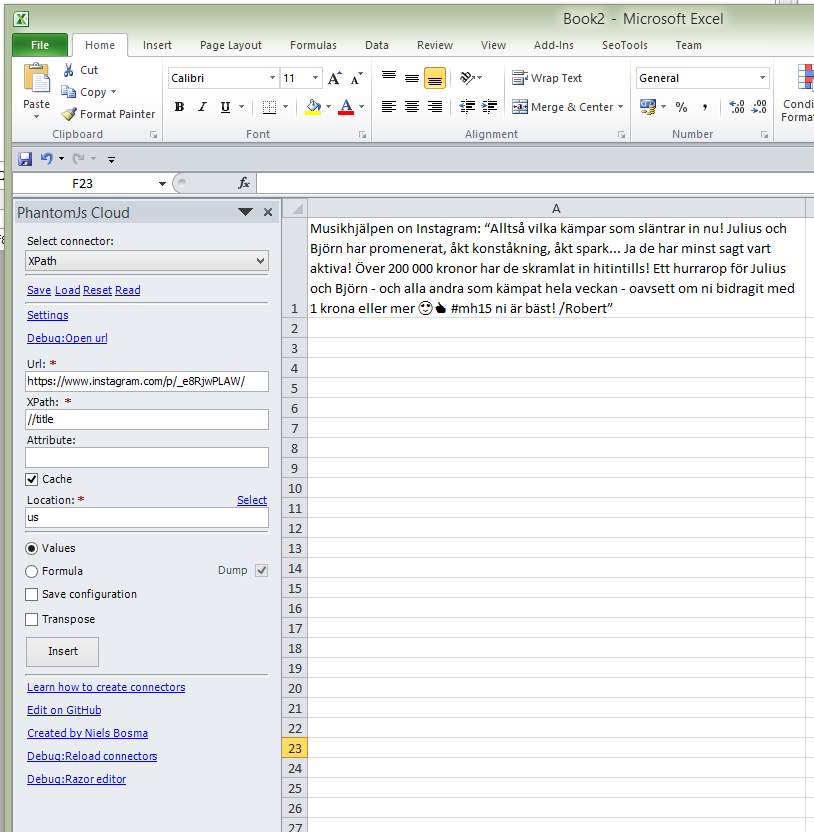
/https://www.instagram.com/p/_e8RjwPLAW/
I get the following text that is cut off:
“Alltså vilka kämpar som släntrar in nu! Julius och Björn har promenerat, åkt konståkning, åkt spark... Ja de har minst sagt vart aktiva! Över 200 000…”
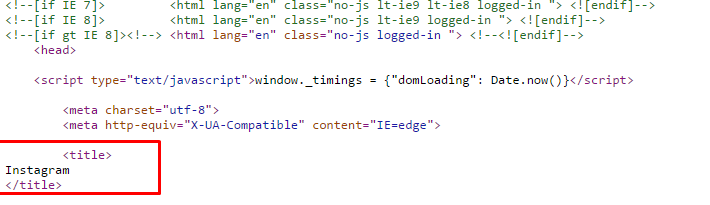
I would like to use Xpath on the tag, because the post, in its entirety, is found here:
/html/head/title when I chose Copy Xpath.
However, I get "Instagram" as a result, because at the top of html page, is:
InstagramIs it any way to force Xpath to extract the text from the /html/head/title path?
Thanks a lot!
/Victor