Hey all, first post / question. (but I did search for my question before posting!)
Let me start out by saying that it seems like the spider tool is likely what I need to use, but I haven't quite figured out how to use it, yet.
I use a number of websites that generate their data based on a variable passed through the URL. Essentially www.websitereportingdomain.com/test?DOMAINBEINGTESTED
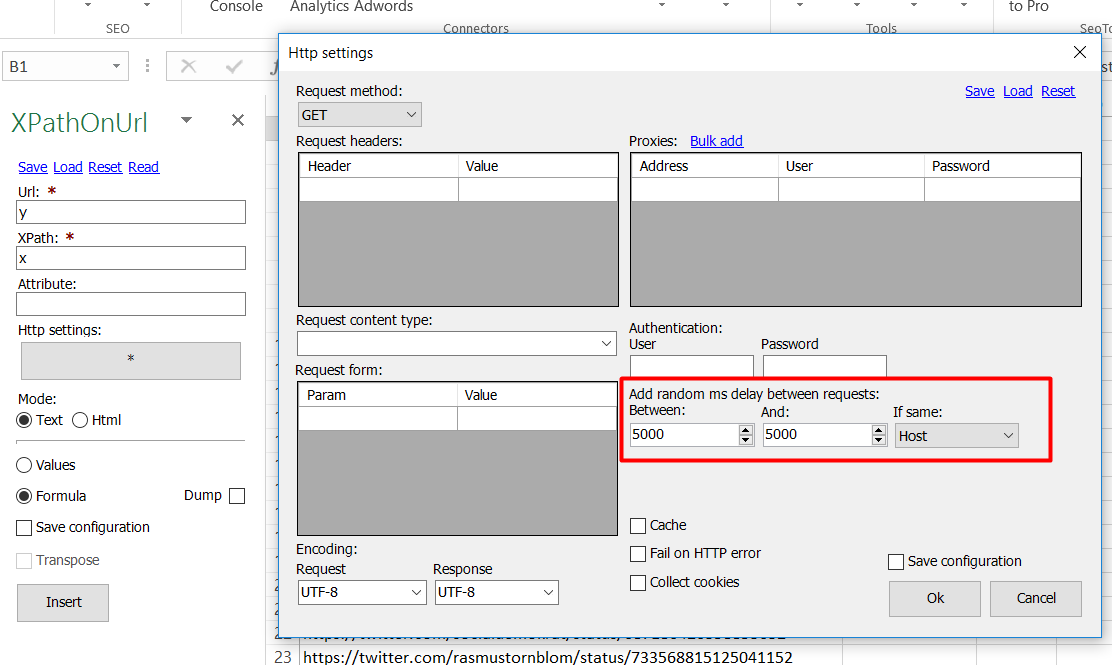
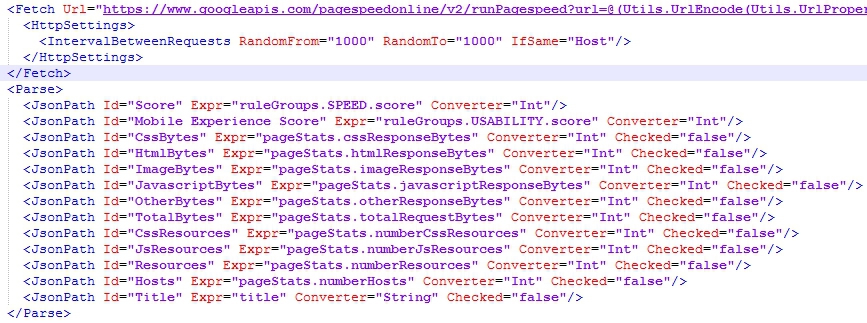
I know I can auto-generate these links using a clever concatenate function in excel and pass them to an XpathOnURL formula. The problem is that it takes 1-3 seconds for the site to generate the report I need.
Since the xPath scrape appears to happen nearly simultaneuously (out of the box, at least), it's scraping info from a container that hasn't yet been populated, and returns a blank result. In another tool, I can set a delay before downloading the data and passing the xPath argument to scrape the data. This is fine, except this other tool isn't feasible for efficient and scalable data mining.
My question is whether or not a delay can be set with xpathonurl that executes the page load, and then waits 1-3 seconds before parsing the site into XML and initiating the xPath scrape.
The added 3 seconds of delay would end up saving me a total of 15 minutes, per report, so I have a lot of energy to get this to work. 
Thanks for any help you can offer!