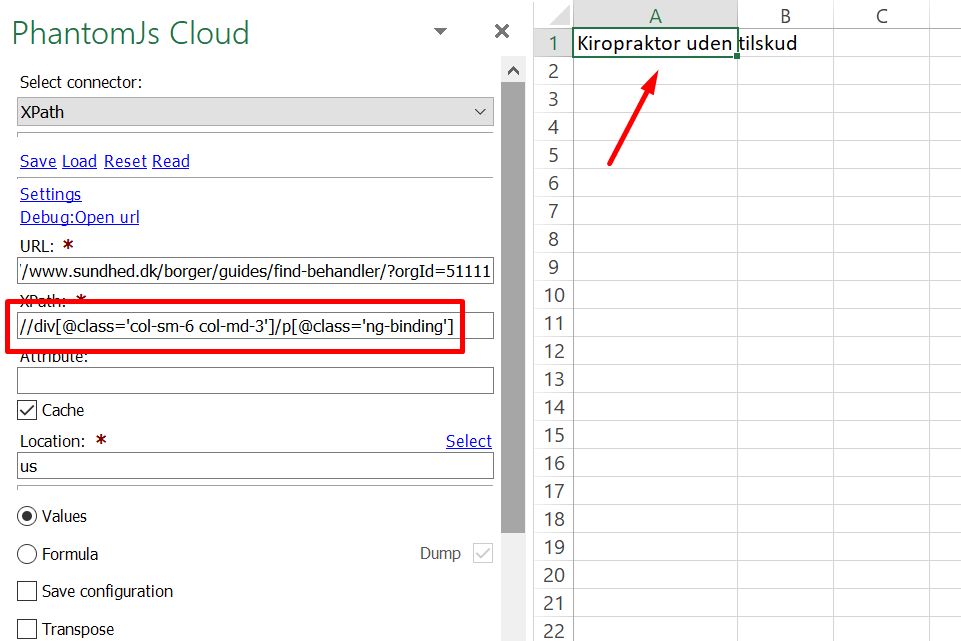
Hi guys!
I am having issues crawling some pages (like this one: https://www.sundhed.dk/borger/guides/find-behandler/?orgId=51111). When I use SEO Tools to 'Get Text on URL' I can tell that it says I am using an outdated browser.
I tried following the blueprint on this page https://seotoolsforexcel.com/httpsettings/ to change the user agent, but I was not successful. Can anyone else get that to work? I was equally unable to 'extract' any content from that particular page with Screaming Frog (no matter which user agent I choose + told it to render javascript).
Can anyone help with this?  Would be greatly appreciated.
Would be greatly appreciated.