Hi everyone, I'm new to the community and SEOTools.
I have a question I'm hoping you can help with.
Full disclosure, I'm not a programmer know enough to be dangerous ... at least to myself 
Here's what I would like to do:
- Go to a specific RSS Feed
- Scrape the title and URL for each article in the RSS feed
- Scrape any Twitter name (e.g. @somename)
- Have each result appear in columns A, B and C. So as an example, the first article in the RSS feed would have the URL in A2, the title in B2, and any Twitter username in C2
When I'm In SEOTools I have the following:
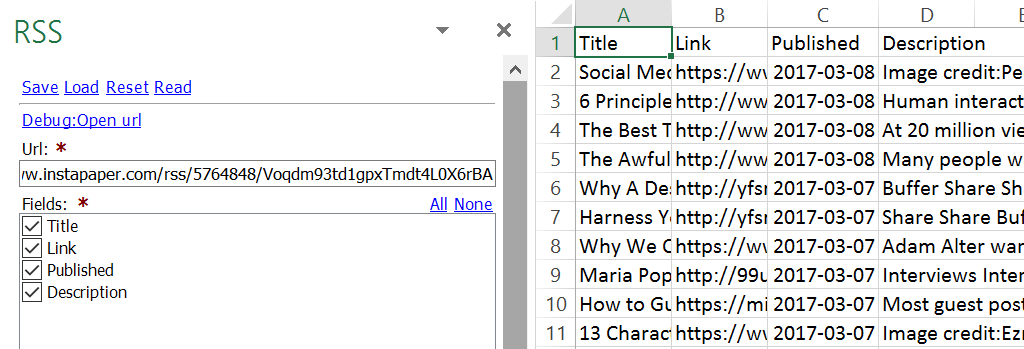
XPathOnURL
URL: The RSS feed is in here
XPath: //link|//title
Mode: Text
Values Selected
When I try the combination above all the results are in column A and looks like
Link1
Title1
Link2
Title2
Link3
Title3
The next combination I try is:
XPathOnURL
URL: The RSS feed is in here
XPath: //link|//title
Mode: Text
Formula selected and Dump is checked off
When I try the combination above it still doesn't work. The same results as before where column A will look like:
Link1
Title1
Link2
Title2
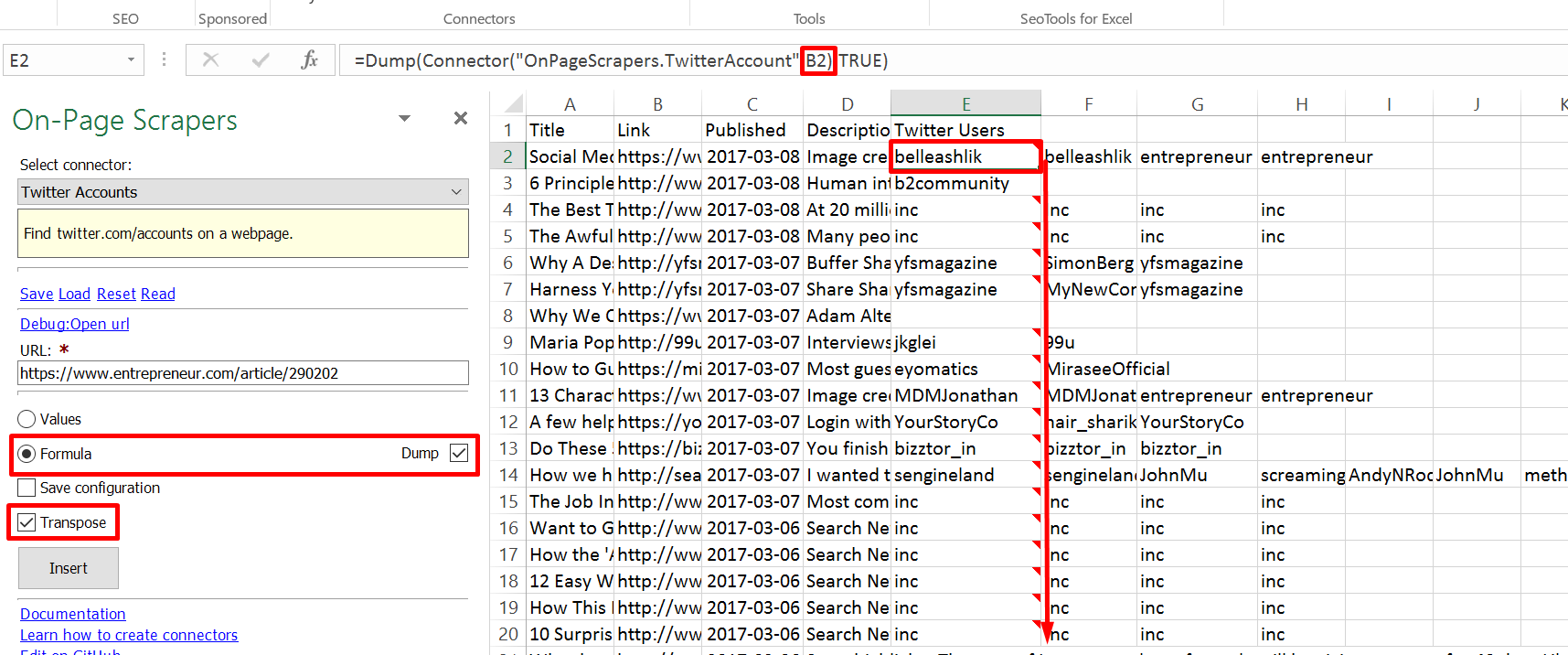
The next combination I try is:
XPathOnURL
URL: The RSS feed is in here
XPath: //link|//title
Mode: Text
Formula selected and Dump is checked off
Transpose selected
When I try the combination above it still doesn't work. Row 1 is filled in across the top and looks like:
Title1 Link1 Title2 Link2
Ideally, the output would like the following:
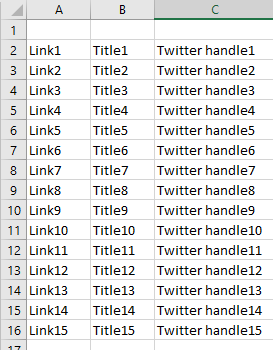
And this brings me to my second question.
How do I configure the On-Page Scrapers to display the Twitter handle in column C?
A big thank you in advance for my newbie question!
Jeffrey